目录
- 高频开奖的魅力:澳洲幸运8每日庞大的数据样本量
- 统计学视角:为什么样本量越大,规律越趋于稳定?
- 高频数据分析的挑战:如何过滤“数据噪音”?
- 时间分段分析法:白天与夜间走势是否存在统计差异?
- 如何利用本站的实时开奖数据进行高效的时间段筛选
在现代数据科学与时间序列分析中,数据的“获取频率”往往决定了分析模型的精度与适用场景。作为高频数据源的典型代表,澳洲幸运8开奖数据以其全天候、不间断的开奖节奏,为统计学研究者和数据爱好者提供了一个极其庞大且连续的样本池。这种高频特征不仅带来了研究的便利,也对传统的统计分析提出了独特的挑战。

高频开奖的魅力:澳洲幸运8每日庞大的数据样本量
对于统计学研究而言,样本量(Sample Size)是决定所有推论可信度的基石。在小样本环境下,极端的偏离值(Outliers)很容易扭曲整体的统计结果。而澳洲幸运8通过高频的开奖机制,在极短的时间内即可累积成千上万期的数据记录。
这种极高的数据密度,使得研究者无需等待数月甚至数年,便能在数天内获取足够支撑复杂统计模型的数据量。与其他高频彩票对比,澳洲幸运8在数据连续性与样本获取速度上展现出了显著的优势,为时间序列走势、均值回归等经典数学理论提供了绝佳的验证环境。
统计学视角:为什么样本量越大,规律越趋于稳定?
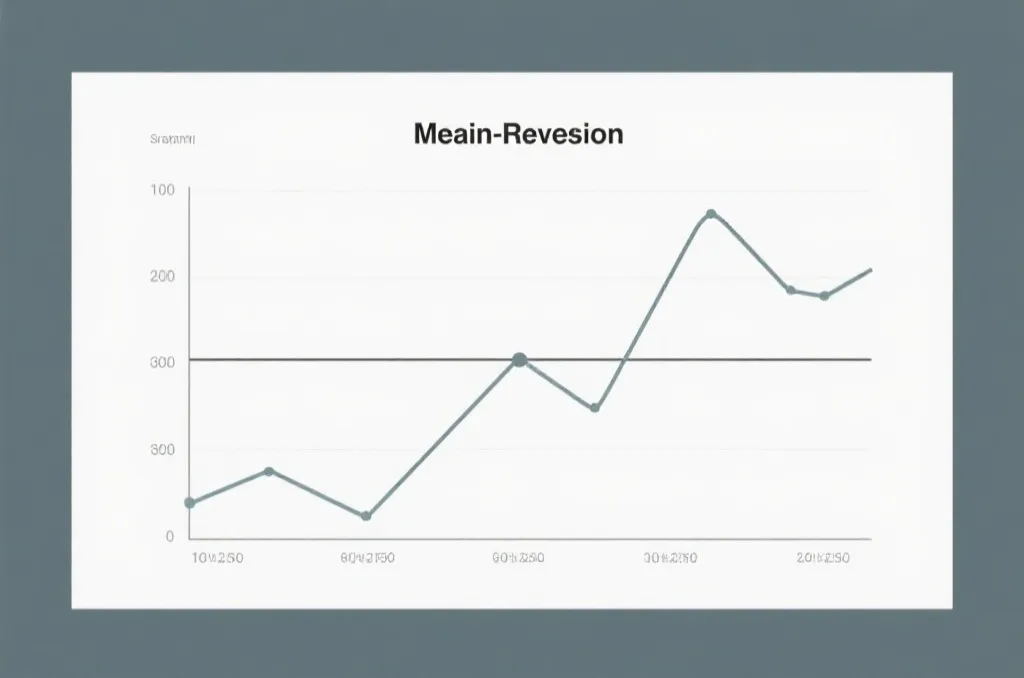
在概率论与数理统计中,大数定律(Law of Large Numbers)指出:在试验不变的条件下,重复试验多次,随机事件的频率近似于它的概率。高频数据最核心的统计学特征,正是它能让“短期偏离”更快地回归均值。
- 加速均值回归:在低频数据中,某项指标连续偏离理论平均值(例如连续出现极值)可能会持续数周,给分析者带来极大的不确定性。而在高频环境下,由于样本量呈指数级增长,这种短期的波动偏离会迅速被后续庞大的常规数据所稀释,使整体走势更快地向理论均值靠拢。
- 提升置信水平:更大的样本量意味着在进行区间估计时,我们能够获得更窄的置信区间,从而显著提高统计推断的精确度。
高频数据分析的挑战:如何过滤“数据噪音”?
然而,高频数据并非只有优势。对于分析者而言,海量的数据同样是一把双刃剑。高频环境最直观的副作用就是“数据噪音(Data Noise)”的泛滥。
在极短的时间跨度内,数据的随机波动(即无规律的白噪声)会表现得异常活跃。如果分析者试图去解释每一次微小的波动,就极易陷入“过度拟合(Overfitting)”和“过度交易(Over-analyzing)”的陷阱,误将随机的噪声当成了必然的规律。为了提取有效的信息,分析者必须学会进行降噪处理,例如采用移动平均线(MA)、指数平滑法,或者将高频数据聚合为“日终数据”或“时段数据”,从而在宏观上把握其真实的统计特征。
时间分段分析法:白天与夜间走势是否存在统计差异?
许多高阶数据分析爱好者喜欢对澳洲幸运8进行“时间分段分析”,例如对比白天(如上午9:00至下午6:00)与夜间的数据走势。那么,从纯粹的统计学和随机性角度来看,不同时间段的数据真的存在本质差异吗?
从底层的随机数生成机制(RNG)来看,每一次开奖都是完全独立的物理/数学事件,其理论概率在全天24小时内是绝对恒定且均等的。因此,在统计学本质上,白天与夜间的开奖概率分布并无任何差异。
然而,了解详细的开奖时间全解析仍然具有实际的数据管理价值。通过将全天数据划分为不同的时间段(如以4小时或8小时为一个区间),分析者可以更方便地进行分段样本抽样,评估在特定样本容量下数据的波动振幅,从而帮助自己建立更理性的期望区间,避免在过度疲劳或情绪波动较大的深夜进行不理性的分析决策。
如何利用本站的实时开奖数据进行高效的时间段筛选
面对全天候不断更新的庞大数据库,手动收集与整理显然是不切实际的。为了帮助高阶分析爱好者更高效地进行高频数据降噪,本站提供了强大且直观的数据过滤与筛选工具。
通过我们平台的实时开奖面板与历史走势图表,您可以轻松实现以下操作:
| 筛选维度 | 应用场景 | 统计学作用 |
|---|---|---|
| 时间段过滤 | 提取特定小时区间的数据样本 | 排除非活跃时段,降低日内干扰 |
| 多期跨度聚合 | 对比50期、100期、500期的走势 | 观察大数定律下的均值回归速度 |
| 冷热值与遗漏值 | 统计特定数值在不同周期的出现频次 | 量化短期偏离度,辅助建立理性预期 |
理性分析的关键在于“以数据为事实,以概率为准绳”。通过科学地对高频数据进行时间段筛选与降噪处理,您将能够穿透表面的随机波动,以更冷静、更宏观的学术视角,洞察高频数据背后的统计学之美。